Video Codecs and Encoding
Video Encoding
비디오 인코딩이란 비디오 원본을 다양한 기기에 호환되는 디지털 형태로 변환하는 과정을 말한다. 라이브 스트리밍에서는 데이터의 빠른 전달과 재생을 위해 비디오 인코딩이 필수적이다.
인코딩은 다양한 기기 또는 소프트웨어에서 실행되며, 유명한 소프트웨어로는 Vmix, Wirecast, OBS Studio 등이 있다.
인코더는 비디오/오디오 코덱을 사용하�여 전달이 용이한 크기로 비디오 원본을 압축한다. 간단히 말하자면, 인코딩은 압축 과정, 코덱은 압축의 수단이라고 볼 수 있다.
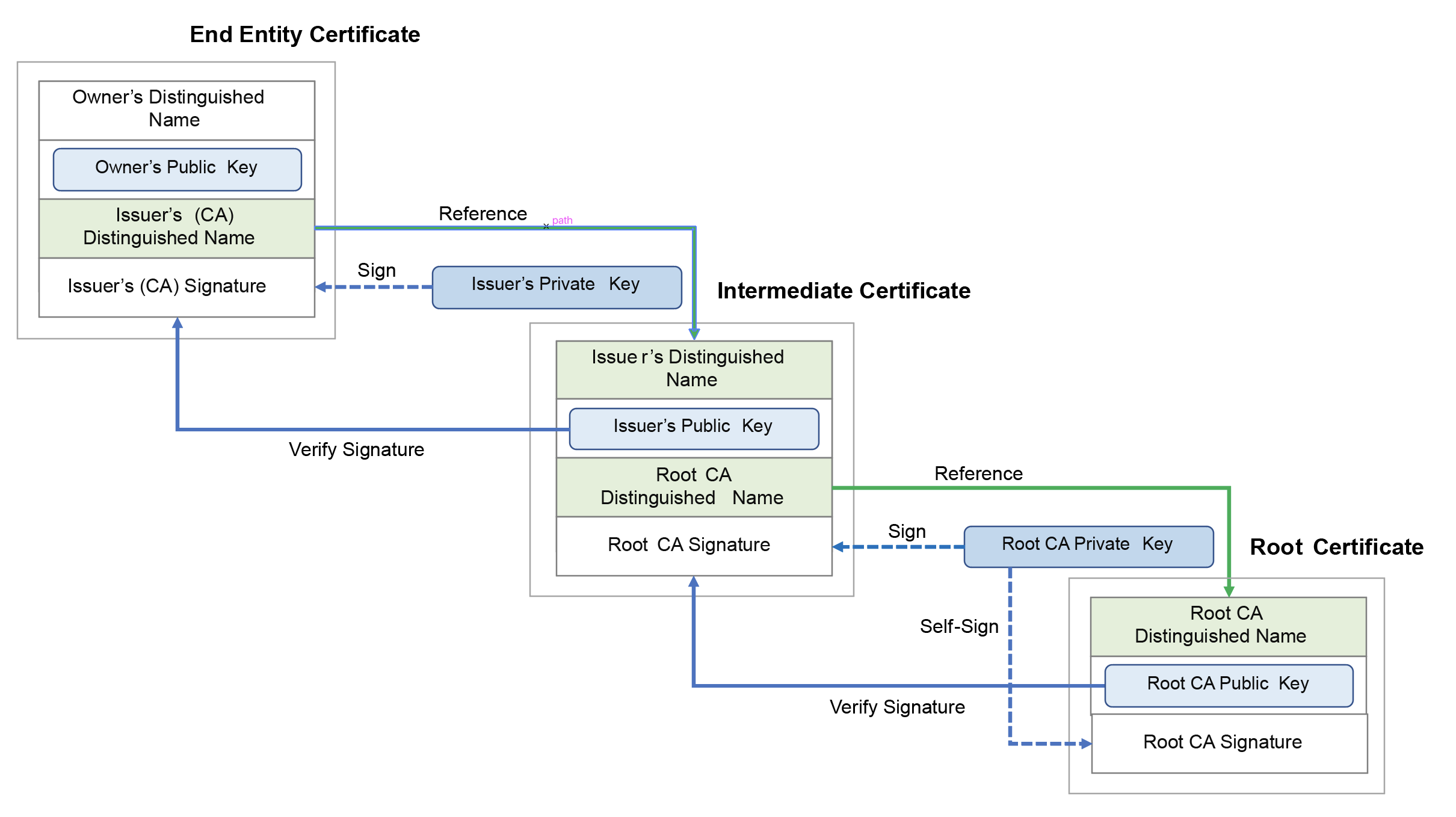
What Is a Codec?
Codec은 coder-decoder, compressor-decompressor의 준말로, 스트리밍의 경우 저장 및 전송을 위해 손실 압축을 적용하며, 추후 재생을 위해 복원된다. H.264는 가장 보편적인 비디오 코덱이며, AAC(Advanced Audio Coding)은 가장 보편적인 오디오 코덱이다.
압축 후, 스트림의 컴포넌트들은 wrapper 또는 파일 포맷으로 패키징된다. 이러한 파일은 오디오/비디오 코덱, CC, 메타데이터를 포함한다. 보편적인 컨테이너로는 .mp4, .mov, .ts, .wmv 등이 있다.
Video Codecs vs Containers: What's the Difference?
코덱은 비디오 원본을 압축하고 복원하며, 전송을 위해 손실 압축을 거치면서 데이터 손실이 발생한다. 반면 비디오 컨테이너는 비디오/오디오 코덱, 자막이나 미리보기 이미지 등의 메타데이터를 모두 저장하여 어떤 프로그램이 스트림을 처리하는지를 결정한다.
Best Video Codecs for Streaming
차세대 코덱은 높은 인코딩 성능과 질을 보여줄 수 있는 반면, 기기 호환성을 보장하기 위해서는 레거시 코덱도 지원하여야 한다. 일례로, 넷플릭스는 최신 코덱 지원을 지속적으로 추가하면서도 서비스 시작부터 지원하였던 VC1 코덱을 계속 지원한다.
H.264/AVC(Advanced Video Coding)
오늘날 대다수의 인코딩 결과는 H.264(=AVC) 파일이다. 주로 AAC 오디오 코덱과 결합되어 사용되며 .mp4, .mov, .F4v, .3GP, .ts 컨테이너에 패키징될 수 있다.
H.264는 거의 모든 기기에서 재생이 가능하며, 높은 품질의 비디오 스트림을 전달하면서도 로열티에 대한 우려가 가장 적다. H.264는 넓은 기기 지원 범위를 바탕으로 높은 점유율을 보여주지만, 4K, HDR(High Dynamic Range) 컨텐츠에는 적합하지 않다. H.264는 빠른 인코딩 속도를 바탕으로 라이브 생성(Live Origination)- 과 Transcoding에 강점을 보이므로 low-latency streaming에 적합하다.
VP9
Google이 개발한 VP9은 로열티가 없는 H.265의 오픈소스 대체 코덱이다. Google의 YouTube와 Chrome 브라우저가 VP9을 지원하며, 안드로이드 기기, Firefox, Safari, 신형 iOS 기기 역시 이를 지원한다. ��또, 많은 WebRTC 워크플로우에서도 VP9을 사용한다. 고성능 비디오에 적합하면서 H.264에 이어 2위의 브라우저/기기 호환성을 보여주어 VP9의 활용폭은 넓어지고 있으며, YouTube와 Netflix의 VP9 사용은 이러한 흐름을 주도할 것으로 보인다.
H.265/HEVC(High Efficiency Video Coding)
H.264의 후속으로 MPEG(Moving Picture Experts Group, ISO/IEC 산하 그룹)에서 개발된 H.265는 압축 효율성 향상과 8K 해상도 지원을 목표로 하며, 실제로 H.264보다 더 작은 결과물 파일을 생성하면서 스트림을 재생하는데 요구하는 대역폭은 더 낮으므로 고해상도 스트리밍에 적합하다. 하지만 코덱 사용 로열티와 특허, 저작권에 대한 불명확성이 있어서 시장 점유율과 호환성이 낮은 편이다. 다만, 대부분의 스마트TV(Living room device)에서 지원되기 때문에 고해상도 OTT 콘텐츠를 제공할 경우에는 H.265가 많이 사용된다.
H.265의 로열티 문제로 인해 Amazon, Netflix, Google, Microsoft, Cisco, Mozila는 AOMedia(Alliance for Open Media)를 결성하여 H.265의 오픈소스 대체 코덱 AV1을 만들었다. 다만 역사가 짧기 때문에 점유율이 높지 않으며, 인코딩 시간이 오래 걸린다는 단점도 있다.
Encoding vs. Transcoding
Transcoding은 인코딩된 파일을 디코딩하여 변환하는 것을 말한다. 이는 데이터를 보다 일반적인 코덱으로 재인코딩하거나, 비디오를 저화질로 변환(transize)하거나, 파일의 비트레이트를 변환(transrate)하거나, 보다 확장성이 높은 프로토콜로 변환(transmux: transcode-multiplexing)하는 등 다양한 과정을 포함한다. 트랜스코딩이 끝나면, 미디어 서버는 파일을 다시 압축한다.
https://www.wowza.com/blog/video-codecs-encoding
 PR을 확인해보니 package-lock.json, package.json, yarn.lock 3개의 파일이 변경된 것을 확인할 수 있었는데, PR의 제목처럼 hexo-renderer-marked라는 패키지의 버전을 업데이트하면서 생긴 변경임을 확인할 수 있었다.
PR을 확인해보니 package-lock.json, package.json, yarn.lock 3개의 파일이 변경된 것을 확인할 수 있었는데, PR의 제목처럼 hexo-renderer-marked라는 패키지의 버전을 업데이트하면서 생긴 변경임을 확인할 수 있었다.